在上一篇文章在Node.js中使用RabbitMQ系列一 Hello world我有使用一个任务队列,不过当时的场景是将消息发送给一个消费者,本篇文章我将讨论有多个消费者的场景。
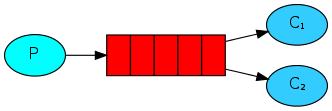
其实,任务队列最核心解决的问题是避免立即处理那些耗时的任务,也就是避免请求-响应的这种同步模式。取而代之的是我们通过调度算法,让这些耗时的任务之后再执行,也就是采用异步的模式。我们需要将一条消息封装成一个任务,并且将它添加到任务队列里面。后台会运行多个工作进程(worker process),通过调度算法,将队列里的任务依次弹出来,并交给其中的一个工作进程进行处理执行。这个概念尤其适合那些HTTP短连接的web应用,它们无法在短时间内处理这种复杂的任务。
准备工作
我们将字符串类型的消息看作是耗时的任务,并且每个字符串消息最后带上一些点。每个点代表该任务需要消耗的秒数。在worker进程处理的时候可以采用setTimeout函数来进行模拟。举个例子:一个伪造的耗时任务是Hello.,则这个任务会消耗1秒,一个伪造的耗时任务是Hello..,则这个任务会消耗2秒,一个伪造的耗时任务是Hello… ,并且这个任务的处理时间会耗费3秒。
这里稍微对上篇文章的send.js文件修改,让它可以发送用户自定义的任意的消息,这个程序会将任务交给任务队列,我们用new_task.js来进行命名:
var q = 'task_queue';
var msg = process.argv.slice(2).join(' ') || "Hello World!";
ch.assertQueue(q, {durable: true});
ch.sendToQueue(q, new Buffer(msg), {persistent: true});
console.log(" [x] Sent '%s'", msg);
我们的receive.js文件也要进行修改,它需要伪造任务的处理时间,让字符串类型的任务看起来需要几秒钟时间(具体取决于 . 的个数)。
ch.consume(q, function(msg) {
var secs = msg.content.toString().split('.').length - 1;
console.log(" [x] Received %s", msg.content.toString());
setTimeout(function() {
console.log(" [x] Done");
}, secs * 1000);
}, {noAck: true});
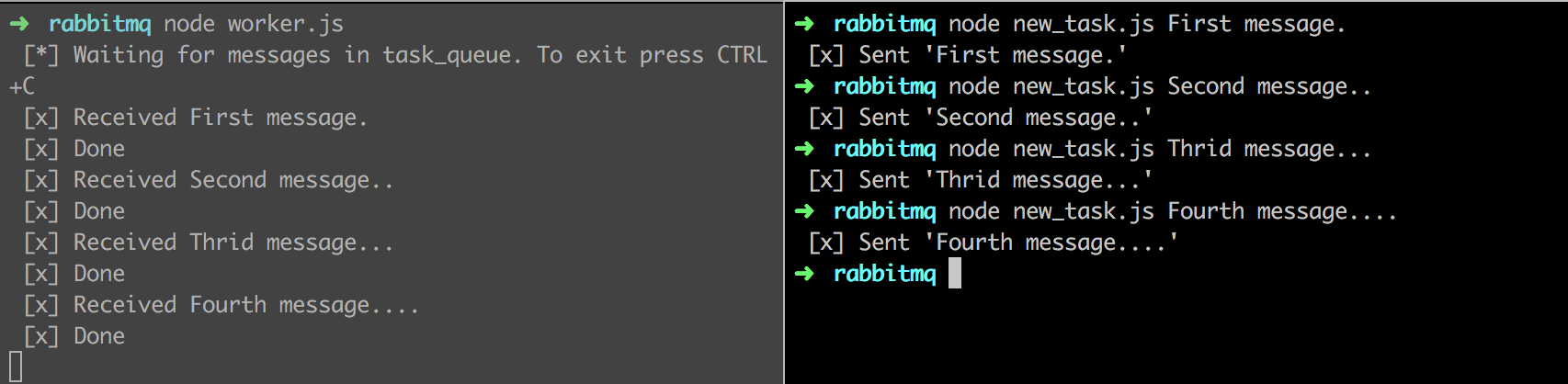
这里以一个worker工作进程为例子,我们先在左侧的shell窗口开启一个worker进程,之后在右侧shell窗口发送自定义的消息,执行看看效果:
轮询调度算法(Round-robin)
使用任务队列的一个优势是能够将任务并行执行,如果需要处理大量的积压任务,我们只需要像上面运行worker进程的方式,增加更多的worker,这个让可伸缩变得更加的容易。
首先,我们使用item2开启2个shell窗口,并在里面运行两个worker进程,但是到底是哪个worker会对消息进行处理呢?这里我们可以做个简单的实验来看看,如下图所示,左侧是两个worker进程,右侧是消息发送端:
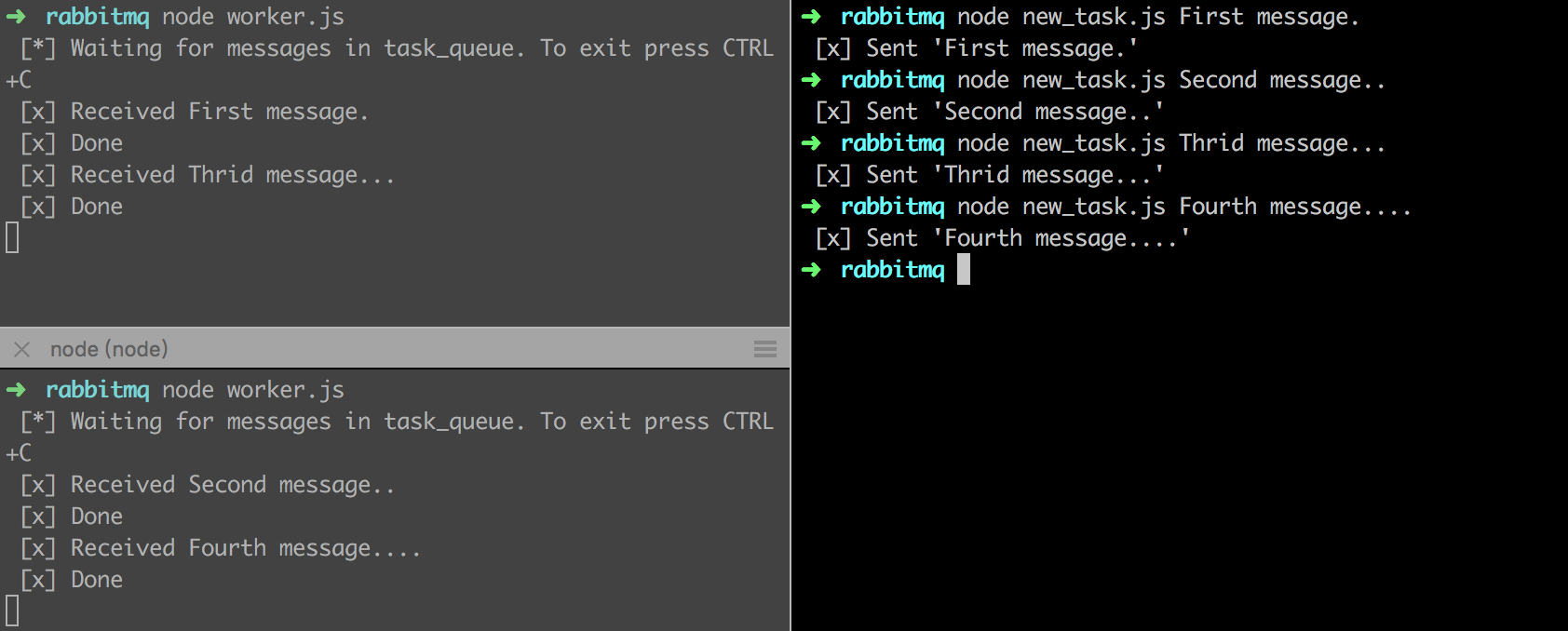
默认情况下,RabbitMQ会采用Round-robin算法来分发任务队列中的任务,每次分发的时候都会将任务派发给下一个消费者,这样每个消费者(worker进程)处理的任务数量其实是一样多的。
消息确认
处理一个复杂的任务需要耗费很长时间,这个时间段里面,可能我们的worker进程由于某种原因挂掉了,这种异常情况是需要考虑的。但是我们现有的代码里面并没有做这种异常的处理,当RabbitMQ将任务派发给worker进程之后,我们立即将这个任务从内存中剔除掉了,设想下,假设worker收到消息之后,我们马上将进程杀死掉,这个时候任务并没有被成功执行的。同时,我们也会丢失所有派发到这个worker进程但是还没有被处理的任务信息。 但是,我们并不想丢掉任何一个任务,如果一个worker进程挂掉,我们更希望能够将这个任务派发给其它的worker来处理。 为了避免任务信息丢失的情况,RabbitMQ支持消息确认。在一个任务发送到了worker进程并且被成功处理完毕之后,一个ack (消息确认)的标识会从消费者发回来告诉RabbitMQ这个任务已经被处理完了,可以将它删除了。 如果一个消费者挂掉了(常见的原因如消息通道关闭了,连接丢失,TCP连接丢失),没有向RabbitMQ发送消息确认这个ack的标识,这个时候RabbitMQ会将它从新加入到队列中,如果有其它消费者存在,那么RabbitMQ会马上将这个任务重新派发下去。之前的例子里面我们并没有开启消息确认这个选项,现在我们可以通过{noAck: false}来开启:
ch.consume(q, function(msg) {
var secs = msg.content.toString().split('.').length - 1;
console.log(" [x] Received %s", msg.content.toString());
setTimeout(function() {
console.log(" [x] Done");
ch.ack(msg);
}, secs * 1000);
}, {noAck: false}); // 开启消息确认标识
可以用CTRL + C来做个实验看看效果。
消息持久化
刚刚谈到,如果一个worker进程挂掉了,不让消息丢失的做法。但是,如果整个RabbitMQ的服务器挂掉了呢?当一个RabbitMQ服务退出或者中断的情况下,它会忘记任务队列里面的消息除非你告诉它不要丢掉,即我们通知RabbitMQ任务队列和这些任务都是需要持久化的。
首先,我们需要确保RabbitMQ永远不会丢失掉我们的任务队列。
ch.assertQueue('hello', {durable: true});
但是,你会发现这样并没有效果,那是因为hello这个队列我们已经定义过,并且指定了它不需要持久化。RabbitMQ不允许我们通过改变参数配置的方式对已经存在的任务队列进行重新定义,因此我们需要定义一个新的任务队列。
ch.assertQueue('task_queue', {durable: true});
这行代码需要同时在生产者和消费者里面的相关代码的地方进行修改。
接下来,我们需要通过配置persistent 选项让我们发送的消息也是持久化的。
ch.sendToQueue(q, new Buffer(msg), {persistent: true});
公平调度
前面的例子,我们讨论了RabbitMQ的调度方式,即采用Round-robin轮询调度算法,因此它会将消息均匀的分配给每个worker进程。RabbitMQ并不会关注每个worker进程有多少个消息没有确认,它只会不断的给你派发任务,不管你能不能处理的过来。这个时候,问题就出现了,设想下,假设有2个worker,其中1个worker刚好很不幸被分配了一个非常复杂的任务,可能需要耗费好几个小时的时间,另外一个worker被分配的任务都比较简单,只需要几分钟就能处理完,由于RabbitMQ的任务分配问题,有很多新的任务依然会分配到那个正在处理很耗时任务的worker上面,这个worker后面的任务都会处于等待状态。幸好,RabbitMQ可以通过prefetch(1)来指定某个worker同时最多只会派发到1个任务,一旦任务处理完成发送了确认通知,才会有新的任务派发过来。
ch.prefetch(1);
最终的代码
new_task.js 代码:
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var q = 'task_queue';
var msg = process.argv.slice(2).join(' ') || "Hello World!";
ch.assertQueue(q, {durable: true});
ch.sendToQueue(q, new Buffer(msg), {persistent: true});
console.log(" [x] Sent '%s'", msg);
});
setTimeout(function() { conn.close(); process.exit(0) }, 500);
});
worker.js:
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var q = 'task_queue';
ch.assertQueue(q, {durable: true});
ch.prefetch(1);
console.log(" [*] Waiting for messages in %s. To exit press CTRL+C", q);
ch.consume(q, function(msg) {
var secs = msg.content.toString().split('.').length - 1;
console.log(" [x] Received %s", msg.content.toString());
setTimeout(function() {
console.log(" [x] Done");
ch.ack(msg);
}, secs * 1000);
}, {noAck: false});
});
});